Reprinted from: Orthomolecular Medicine News Service, December 7, 2011
(OMNS, Dec 7, 2011) Evidence-based medicine (EBM) is the practice of treating individual patients based on the outcomes of huge medical trials. It is, currently the self-proclaimed gold standard for medical decision-making, and yet it is increasingly unpopular with clinicians. Their reservations reflect an intuitive understanding that something is wrong with its methodology. They are right to think this, for EBM breaks the laws of so many disciplines that it should not even be considered scientific. Indeed, from the viewpoint of a rational patient, the whole edifice is crumbling.
The assumption that EBM is good science is unsound from the start. Decision science and cybernetics (the science of communication and control) highlight the disturbing consequences. EBM fosters marginally effective treatments, based on population averages rather than individual need. Its mega-trials are incapable of finding the causes of disease, even for the most diligent medical researchers, yet they swallow up research funds. Worse, EBM cannot avoid exposing patients to health risks. It is time for medical practitioners to discard EBM’s tarnished gold standard, reclaim their clinical autonomy, and provide individualized treatments to patients.
The key element in a truly scientific medicine would be a rational patient. This means that those who set a course of treatment would base their decision-making on the expected risks and benefits of treatment to the individual concerned. If you are sick, you want a treatment that will work for you, personally. Given the relevant information, a rational patient will choose the treatment that will be most beneficial. Of course, the patient is not in isolation but works with a competent physician, who is there to help the patient. The rational decision making unit then becomes the doctor-patient collaboration.
The idea of a rational doctor-patient collaboration is powerful. Its main consideration is the benefit of the individual patient. However, EBM statistics are not good at helping individual patients. Rather, they relate to groups and populations.
The Practice of Medicine
Nobody likes statistics. Okay, that might be putting it a bit strongly but, with obvious exceptions (statisticians and mathematical types), many people do not feel comfortable with statistical data. So if you feel inclined to skip this article in favor of something more agreeable, please wait a minute. For although we are going to talk about statistics, our ultimate aim is to make medicine simpler to understand and more helpful to each individual patient.
The current approach to medicine is “evidence-based.” This sounds obvious but, in practice, it means relying on a few large-scale studies and statistical techniques to choose the treatment for each patient. Practitioners of EBM incorrectly call this process using the “best evidence.” In order to restore the authority for decision-making to individual doctors and patients, we need to challenge this orthodoxy, which is no easy task. Remember Linus Pauling: despite being a scientific genius, he was condemned just for suggesting that vitamin C could be a valuable therapeutic agent.
Historically, physicians, surgeons and scientists with the courage to go against prevailing ideas have produced medical breakthroughs. Examples include William Harvey’s theory of blood circulation (1628), which paved the way for modern techniques such as cardiopulmonary bypass machines; James Lind’s discovery that limes prevent scurvy (1747); John Snow’s work on transmission of cholera (1849); and Alexander Fleming’s discovery of penicillin (1928). Not one of these innovators used EBM. Rather, they followed the scientific method, using small, repeatable experiments to test their ideas. Sadly, practitioners of modern EBM have abandoned the traditional experimental method, in favor of large group statistics.
What Use are Population Statistics?
Over the last twenty years, medical researchers have conducted ever larger trials. It is common to find experiments with thousands of subjects, spread over multiple research centers. The investigators presumably believe their trials are effective in furthering medical research. Unfortunately, despite the cost and effort that go into them, they do not help patients. According to fundamental principles from decision science and cybernetics, large-scale clinical trials can hardly fail to be wasteful, to delay medical progress, and to be inapplicable to individual patients.
Much medical research relies on early twentieth century statistical methods, developed before the advent of computers. In such studies, statistics are used to determine the probability that two groups of patients differ from each other. If a treatment group has taken a drug and a control group has not, researchers typically ask whether any benefit was caused by the drug or occurred by chance. The way they answer this question is to calculate the “statistical significance.” This process results in a p-value: the lower the p-value, the less likely the result was due to chance. Thus, a p-value of 0.05 means a chance result might occur about one time in 20. Sometimes a value of less than one-in-one-hundred (p < 0.01), or even less than one-in-a-thousand (p < 0.001) is reported. These two p-values are referred to as “highly significant” or “very highly significant” respectively.
Significant Does Not Mean Important
We need to make something clear: in the context of statistics, the term significant does not mean the same as in everyday language. Some people assume that “significant” results must be “important” or “relevant.” This is wrong: the level of significance reflects only the degree to which the groups are considered to be separate. Crucially, the significance level depends not only on the difference between the studied groups, but also on their size. So, as we increase the size of the groups, the results become more significant-even though the effect may be tiny and unimportant.
Consider two populations of people, with very slightly different average blood pressures. If we take 10 people from each, we will find no significant difference between the two groups because a small group varies by chance. If we take a hundred people from each population, we get a low level of significance (p < 0.05), but if we take a thousand, we now find a very highly significant result. Crucially, the magnitude of the small difference in blood pressure remains the same in each case. In this case a difference can be highly significant (statistically), yet in practical terms it is extremely small and thus effectively insignificant. In a large trial, highly significant effects are often clinically irrelevant. More importantly and contrary to popular belief, the results from large studies are less important for a rational patient than those from smaller ones.
Large trials are powerful methods for detecting small differences. Furthermore, once researchers have conducted a pilot study, they can perform a power calculation, to make sure they include enough subjects to get a high level of significance. Thus, over the last few decades, researchers have studied ever bigger groups, resulting in studies a hundred times larger than those of only a few decades ago. This implies that the effects they are seeking are minute, as larger effects (capable of offering real benefits to actual patients) could more easily be found with the smaller, old-style studies.
Now, tiny differences – even if they are “very highly significant” – are nothing to boast about, so EBM researchers need to make their findings sound more impressive. They do this by using relative rather than absolute values. Suppose a drug halves your risk of developing cancer (a relative value). Although this sounds great, the reported 50% reduction may lessen your risk by just one in ten thousand: from two in ten thousand (2/10,000) to one in ten thousand (1/10,000) (absolute values). Such a small benefit is typically irrelevant, but when expressed as a relative value, it sounds important. (By analogy, buying two lottery tickets doubles your chance of winning compared to buying one; but either way, your chances are miniscule.)
The Ecological Fallacy
There is a further problem with the dangerous assertion implicit in EBM that large-scale studies are the best evidence for decisions concerning individual patients. This claim is an example of the ecological fallacy, which wrongly uses group statistics to make predictions about individuals. There is no way round this; even in the ideal practice of medicine, EBM should not be applied to individual patients. In other words, EBM is of little direct clinical use. Moreover, as a rule, the larger the group studied, the less useful will be the results. A rational patient would ignore the results of most EBM trials because they aren’t applicable.
To explain this, suppose we measured the foot size of every person in New York and calculated the mean value (total foot size/number of people). Using this information, the government proposes to give everyone a pair of average-sized shoes. Clearly, this would be unwise-the shoes would be either too big or too small for most people. Individual responses to medical treatments vary by at least as much as their shoe sizes, yet despite this, EBM relies on aggregated data. This is technically wrong; group statistics cannot predict an individual’s response to treatment.
EBM Selects Evidence
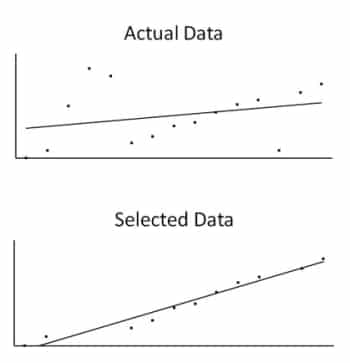
Another problem with EBM’s approach of trying to use only the “best evidence” is that it cuts down the amount of information available to doctors and patients making important treatment decisions. The evidence allowed in EBM consists of selected large-scale trials and meta-analyses that attempt to make a conclusion more significant by aggregating results from wildly different groups. This constitutes a tiny percentage of the total evidence. Meta-analysis rejects the vast majority of data available, because it does not meet the strict criteria for EBM. This conflicts with yet another scientific principle, that of not selecting your data. Rather humorously in this context, science students who select the best data, to draw a graph of their results, for example, will be penalized and told not to do it again.
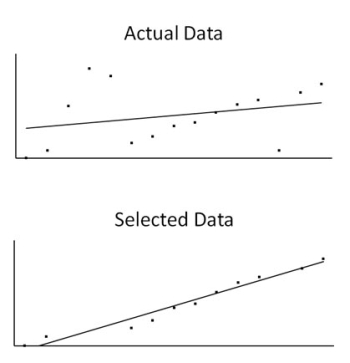
One of the first lessons for science students is to not select the best evidence; all data must be considered. The lines indicate how using just the “best” data gives a better, though misleading, fit.
More EBM Problems
The problems with EBM continue. It breaks other fundamental laws, this time from the field of cybernetics, which is the study of systems control and communication. The human body is a biological system and, when something goes wrong, a medical practitioner attempts to control it. To take an example, if a person has a high temperature, the doctor could suggest a cold compress; this might work if the person was hot through over-exertion or too many clothes. Alternatively, the doctor may recommend an antipyretic, such as aspirin. However, if the patient has an infection and a raging fever, physical cooling or symptomatic treatment might not work, as it would not quell the infection.
In the above case, a doctor who overlooked the possibility of infection has not applied the appropriate information to treat the condition. This illustrates a cybernetic concept known as requisite variety, first proposed by an English psychiatrist, Dr. W. Ross Ashby. In modern language, Ashby’s law of requisite variety means that the solution to a problem (such as a medical diagnosis) has to contain the same amount of relevant information (variety) as the problem itself. Thus, the solution to a complex problem will require more information than the solution to a straightforward problem. Ashby’s idea was so powerful that it became known as the first law of cybernetics. Ashby used the word variety to refer to information or, as an EBM practitioner might say, evidence.
As we have mentioned, EBM restricts variety to what it considers the “best evidence.” However, if doctors were to apply the same statistically-based treatment to all patients with a particular condition, they would break the laws of both cybernetics and statistics. Consequently, in many cases, the treatment would be expected to fail, as the doctors would not have enough information to make an accurate prediction. Population statistics do not capture the information needed to provide a well-fitting pair of shoes, let alone to treat a complex and particular patient. As the ancient philosopher Epicurus explained, you need to consider all the data.
Restricting our information to the “best evidence” would be a mistake, but it is equally wrong to go to the other extreme and throw all the information we have at a problem. Just as Goldilocks in the fairy-tale wanted her porridge “neither too hot, nor too cold, but just right” doctors must select just the right information to diagnose and treat an illness. The problem of too much information is described by the quaintly-named curse of dimensionality, discussed further below.
A doctor who arrives at a correct diagnosis and treatment in an efficient manner is called, in cybernetic terms, a good regulator. According to Roger Conant and Ross Ashby, every good regulator of a system must be a model of that system. Good regulators achieve their goal in the simplest way possible. In order to achieve this, the diagnostic processes must model the systems of the body, which is why doctors undergo years of training in all aspects of medical science. In addition, each patient must be treated as an individual. EBM’s group statistics are irrelevant, since large-scale clinical trials do not model an individual patient and his or her condition, they model a population-albeit somewhat crudely. They are thus not good regulators. Once again, a rational patient would reject EBM as a poor method for finding an effective treatment for an illness.
Real Science Means Verification
As we have implied, science is a process of induction and uses experiments to test ideas. From a scientific perspective, therefore, we trust but verify the findings of other researchers. The gold standard in science is called Solomonoff Induction, named after Ray Solomonoff, a cybernetic researcher. The power of a scientific result is that you can easily repeat the experiment and check it. If it can’t be repeated, for whatever reason (because it is untestable, too difficult, or wrong), a scientific result is weak and unreliable. Unfortunately, EBM’s emphasis on large studies makes replication difficult, expensive, and time consuming. We should be suspicious of large studies, because they are all but impossible to repeat and are therefore unreliable. EBM asks us to trust its results but, to all intents and purposes, it precludes replication. After all, how many doctors have $40 million dollars and 5 years available to repeat a large clinical trial? Thus, EBM avoids refutation, which is a critical part of the scientific method.
In their models and explanations, scientists aim for simplicity. By contrast, EBM generates large numbers of risk factors and multivariate explanations, which makes choosing treatments difficult. For example, if doctors believe a disease is caused by salt, cholesterol, junk food, lack of exercise, genetic factors, and so on, the treatment plan will be complex. This multifactorial approach is also invalid, as it leads to the curse of dimensionality. Surprisingly, the more risk factors you use, the less chance you have of getting a solution. This finding comes directly from the field of pattern recognition, where overly complex solutions are consistently found to fail. Too many risk factors mean that noise and error in the model will overwhelm the genuine information, leading to false predictions or diagnoses. Once again, a rational patient would reject EBM, because it is inherently unscientific and impractical.
Medicine for People, Not Statisticians
Diagnosing medical conditions is challenging, because we are each biochemically individual. As explained by an originator of this concept, nutritional pioneer Dr. Roger Williams, “Nutrition is for real people. Statistical humans are of little interest.” Doctors must encompass enough knowledge and therapeutic variety to match the biological diversity within their population of patients. The process of classifying a particular person’s symptoms requires a different kind of statistics (Bayesian), as well as pattern recognition. These have the ability to deal with individual uniqueness.
The basic approach of medicine must be to treat patients as unique individuals, with distinct problems. This extends to biochemistry and genetics. An effective and scientific form of medicine would apply pattern recognition, rather than regular statistics. It would thus meet the requirements of being a good regulator; in other words, it would be an effective approach to the prevention and treatment of disease. It would also avoid traps, such as the ecological fallacy.
Personalized, ecological, and nutritional (orthomolecular) medicines are converging on a truly scientific approach. We are entering a new understanding of medical science, according to which the holistic approach is directly supported by systems science. Orthomolecular medicine, far from being marginalized as “alternative,” may soon become recognized as the ultimate rational medical methodology. That is more than can be said for EBM.
About the Authors:
Steve Hickey holds a PhD in Medical Biophysics from the University of Manchester, England. His PhD was on the development, aging, function and failure of the intervertebral disk. He carried out research in the fields of medical imaging and biophysics, and his later research included pattern recognition, artificial intelligence, computer science, and decision science. He has published hundreds of scientific articles in a variety of disciplines. Dr. Hickey is co-author, with Hilary Roberts, of Ascorbate: The Science of Vitamin C; Cancer: Nutrition and Survival; Ridiculous Dietary Allowance; The Cancer Breakthrough, and The Vitamin Cure for Heart Disease.
Hilary Roberts has her PhD in the effects of early-life undernutrition from the Department of Child Health at the University of Manchester, England. She also holds degrees in computer science, physiology and psychology. Following her PhD, she carried out research into the development of expert systems at Manchester Business School, England.
OMNS: Free subscription link:http://orthomolecular.org/subscribe.html
Archive link:http://orthomolecular.org/resources/omns/index.shtml



In a visit to my (American) allopathic family doctor a couple of years ago, she used the term, “Evidence-Based Medicine,” so I responded, “Evidence of what – that it cures the disease? Or do you mean evidence that it suppresses the symptoms?”
Allopathic docs are good for a few things but curing anybody isn’t on the list.