Introduction
Is the Randomized Double Blind Placebo Controlled Trial (RDBPCT, or RCT) an objective scientific instrument? The short answer is “yes.” A useful answer is more complicated.
Basically, the answer to this question is in fact an unqualified “yes.” And, so there is no mistake, let me specify that by ‘objective’ I intend to suggest that the observations recorded in the blinded trial reflect actual facts – that is, events or objects (trial outcomes) – and that the facts so reflected are accurately recorded. That is what the RCT does: it is like a camera. It records what you put in front of it.
In fact, the RCT is certainly superior to the camera in its perfect, or nearly perfect performance, but it is not without problems. In any case, problems with the RCT are similar enough to problems with the camera, to make the analogy illustrative: the camera can record what you put before it, but someone has to pose the subject (in research, we use the trial protocol) and someone has to develop the film (even in a digital camera, the ability of the image to represent the real object is dependent on the digital media: how many megapixels, to reference only the most obvious variable). The best camera in the world will produce only useless images, if the subject is posed poorly, or the film developed (interpreted) by a fool. Posing the subject, in research is represented by the necessity of designing the experimental protocol. And for “development of the film” we use a second, usually unremarked level of observation, namely, selection and interpretation of outcome data – this fact seems to be especially difficult to see, for the research scientist, who appears to operate on the assumption that numbers speak for themselves. Although he will agree that this is not true, examination of the way in which statistical results of trials are presented, of the conclusions that are drawn from those numbers, reflects that the ability to examine one’s own assumptions, or even recognize one is making them, is often difficult of realization.
Both processes, of posing and developing (designing and interpreting) are, further, dependent on selection of an appropriate object in the first place: if we want to photograph a radio signal, with a standard optical camera – film or digital – we will fail. And if we want to photograph a rapidly moving object, the wrong camera will provide only a blur. Thus, we conclude – or will conclude – that the quality of observations made by the RCT will be at least partly dependent on its suitability for measuring the observations placed before it – specifically, in other words, in this paper we will be concerned whether the RCT is an appropriate instrument for measuring processes in homeopathic medicine.
I propose in the following to analyze each of the major elements of the RCT: randomization, blinding, and the placebo control. The greater part of this analysis will focus on the blinding process, and the key question, “are trial outcomes – which we acknowledge to be accurately recorded – representative of events in the real world, or do they reflect spurious products of inadequately realized experimental replicas of real-world processes? In short, the problem posed for the present essay is not, strictly, whether the RCT format objectively records trial outcomes, but whether the trial itself, the individual realization of the idealized RCT format, has been adequately calibrated to the object of study. A camera (RCT) that photographs an object through a fog, will appear to produce an image of the original object, but a more useful statement would be that it produced an image of the original object as obscured or altered by the intervening atmospheric disturbance.
Randomization will be dealt with briefly in this paper: for the most part, it will be shown that randomization introduces only a few limitations to the utility of the RCT in scientific investigation. The placebo control, on the other hand, is reviewed in somewhat more detail, as its appropriateness to measuring medical efficacy is more central to the issue at hand, the differing models of action as between conventional and homeopathic medicine. Further, the effects introduced into poorly designed studies are more problematic and much more surprising than hitherto suspected, and deserve close attention.
It will come as no surprise to anyone even vaguely familiar with the history of discovery in science, that, by definition of course, “discovery” (new knowledge) implies that earlier beliefs have been supplanted, or in currently popular terminology, ‘falsified.’ It is time, in short, to recognize that utilization of the RCT in scientific experimentation is not the mindlessly simple procedure that the rabid skeptic likes to maintain: although the instrument itself is easy to use, selection of appropriate objects for study is more difficult than appears on superficial examination … and, the ideal that the controlled trial is well matched to studying homeopathy, itself deserves to be closely examined.
The Randomized Double Blind Placebo Controlled Trial
When historians look back, the last two to three decades will be considered part of the “prehistory” of research into homeopathic medicine. From the vantage point of the future, the work done in this period will be understood as having been deeply flawed, in applying a research model derived from one method of practice, without modification, to a distinctly different practice and theoretical model. In our particular situation, we will see that trial designs useful for representing conventional medicine to the observing eye of the RCT are not as well suited to representing the mechanisms and dynamics of the healing process in homeopathic medicine. The problems thus introduced lead to systematic repetition of errors in measuring homeopathic efficacy.
It is often argued that the primary distinction, between homeopathic and conventional medicine, is that conventional medicine treats discrete disease entities, while homeopathy treats the “totality,” the symptom picture of the whole person. But this seems to me to miss the point, at least from the research point of view, as “totality” from this angle is really nothing more than a “better diagnosis.” But, whether we are talking about a discrete syndrome or “the totality,” from the research point of view the question is the same: is homeopathy superior to placebo, or not? Were this the only question, there would be no reason research protocols, designed for testing conventional medicines, could not be applied, without modification, to successful trials of homeopathic remedies.
But the essential question involves this fact, that conventional medications aim primarily to eliminate symptoms, while homeopathic remedies aim primarily to produce them. I confess, it is difficult for me to understand how educated people, on both sides of the controversy, can so consistently miss, or disregard, the implications of such a basic element of practice. To place the issue in more common parlance, dealing with homeopathy is like using the double negative in speech: understanding what is being said, or what is happening in the treatment situation, is not so obvious as might be expected.
In any case, through the methodological confusion introduced by this omission, current research – albeit, in spite of itself – has thus contributed to our understanding that the instrumentation of the double blind is an idealized model of a process, an archetypal instrument, but one that nevertheless must be well adapted, or fit, to the specific object of investigation, or discarded in favor of other instruments, and at the very least handled with care, that is, paying due attention to couching findings in suitably tentative language. By way of analogy – that is, to illuminate, but not to prove nor to demonstrate – the “dish” may be a basic element in design of astronomical observational equipment, but an optical dish, a mirror, no matter how perfectly manufactured nor how precise its observations, will never succeed in producing evidence of radio emissions from deep space. But that does not justify us in concluding, that there are no radio sources in deep space.
It is true, of course, that the process of blinding protects against observer bias, regardless the object being observed, and it is this fact that lies behind the typical skeptic attitude that it is ‘easy’ to design a trial of homeopathy, or anything else, on the assumption that it does not matter how a trial’s outcomes are produced (e.g., by conventional medical treatment or by homeopathy), since the double blind mechanism works the same in either case. What skeptics miss – universally, it seems – is this: a guarantee that the observation of trial outcomes is objective or accurate, does not guarantee that the outcomes themselves accurately represent processes, or outcomes, in the real world. In other words, if or to the degree the experimental design distorts the character of the process it seeks to test, then the results it produces will not accurately reflect that process; and the ability of blinded observation to accurately record test results will likewise, in that case, contribute little or possibly nothing to an understanding of the real process observed in the real world.
Researchers should incorporate into their theoretical schemas, the idea that blinded observation can and will produce an objective and accurate record of experimental outcomes – that is in its nature, that is what it does – but that the correlation of those outcomes to real world processes must be achieved through the experimental setup itself, essentially, the protocol. But the latter has no intrinsic merits, as does the mechanism of the double blind; rather, the protocol has to be designed from scratch, for each new effort to measure this or that subject of experimental investigations. Designing the protocol represents, in essence, the act of calibrating the idealized RCT to the characteristic features of the medical practices being examined.
A common mistake among those not familiar with research technology, is to object that animals and very young children, who by their natures can not ‘report’ how they feel, will nevertheless show improvement after homeopathic treatment. The uninitiated concludes, therefore, that there can have been no placebo effect in the healthful response of the patient to the homeopathic remedy. But, to permit those novices to appreciate the present essay more adequately, it should be observed that the biased observation, which is excluded by the double blind methodology, includes the observations and opinions of the parent, pet owner, or physician. In short, we don’t need the infant or the pet to say, “Gee, Ars Alb really helped me feel better.” The proud papa or mama does fine by himself, in introducing bias into the proceedings!
In any case, the double blind is a formal template or instrument that may be used for many purposes, and it will accurately measure whatever you give it to measure. But the experiment itself, the trial, or the protocol, is the creation of the individual researcher or research team. Its quality is completely dependent on the ability of the research team to understand the real situation, and to design an experiment that fairly represents the actual nature of the process or object under investigation. If they can’t do that, then the double-blinded trial will do nothing more than accurately record the mistakes and misrepresentations of the experimental protocol:
If you put two flashlights – one with a light bulb in it, and the other without – in a black box, and ask observers to tell when one or the other flashlight has been turned on, the randomized, double blind trial will tell you that the verum flashlight performed no better than the placebo flashlight.
We may note, without objection, that this is an accurate reading of the outcomes of the trial. But, of course, these outcomes do not reflect how the two flashlights really performed, for their actual performance occurred within the black box and was not directly observed.
All that is observed by the double-blinded trial format, are the outcomes produced, or permitted, by the experimental design. If the trial design is bad, the outcomes will have no bearing on the real world, and the accuracy of the blinded observations will have no more relationship to reality than does the illusion of the magician pulling a rabbit out of his hat: we’ve all seen that trick, too. Further, an object of experimentation may be inappropriate for a blinded trial in the first place – in the manner of a radio source to an optical telescope; in that situation, though the blinding process itself may produce a perfectly objective record of trial outcomes, that record will nevertheless be useless. In short, we will have reached the boundary at which suitability of the RCT to particular objects, including specific medical practices, has been crossed. The proposition that the RCT can be applied with ease to the study of homeopathy will have been falsified.
The RCT and Homeopathy: Elimination vs. Production of Symptoms
The Randomized Double Blind Placebo Controlled Trial, as the child of recent developments in statistical science, cut its admittedly remarkable teeth on the efficacy trial of conventional (or “allopathic”) medication. To take a simplified, or “idealized” model of the challenge faced in such an efficacy trial, we may conceptualize the action of conventional medications as directed toward a discrete symptom, for example, aspirin to pain.
Certainly, there are fine and even significant points of differentiation, as between one pain medication and another; furthermore, there are medications that are directed toward a broader range of pathology than can be specified by a single symptom; and certainly there are “allopathic” medications that aim to do more than merely suppress symptoms. But the essential purpose of the efficacy trial is unchanged by this, and that is to measure whether the medication has an effect in eliminating a symptom. Indeed, in this regard, the efficacy trial is indistinguishable from the treatment trial, and may in fact be considered a focused variation on the treatment trial.
By contrast, the “efficacy” trial in homeopathy, more accurately called a “proving trial,” has its purpose to demonstrate whether the remedy in question can produce symptoms, not eliminate them. Further, a glance at the materia medica reveals that even the least productive remedies are capable of provoking numerous symptoms in the patient, or prover, while the “largest” remedies may produce many hundreds of symptoms. In an earlier paper on this subject,1 I pointed to the example of Belladonna, regarding which Hahnemann lists, in the Materia Medica Pura, 1,440 symptoms.
Immediately, we see that the efficacy trial of “aspirin” needs only to look in one place, to see whether the medication is working. By contrast, to document “effect” of the homeopathic remedy, research must have the ability to identify the complete spectrum of a remedy’s action, that is, to identify participant response as verum symptom, regardless which of the 1,440 symptoms he produces. This point of view may be challenged, of course, for example, by the view that a remedy may be tested against a selection of proving symptoms, on the assumption that verum should still outperform placebo, proportionately, within this more limited field, an assumption that lays behind the model used in the Belladonna proving trial discussed in an earlier paper.
Nevertheless, designing a trial protocol on this basis introduces an added burden to the research team, of justifying their hypothesis, that it is fair to extrapolate results produced through such a design, to an evaluation of performance of the remedy across the full range of its action. Some of the problems with this assumption were addressed in my aforementioned paper;1 I will now proceed to a further consideration of this interesting subject.
The RCT and Homeopathy: Placebo and Placebo Response.
With regard to this problem, for our present purposes, I would stipulate in particular:
first, that individual response to a remedy, by trial participants, is by definition selective, and, therefore, that there is no way to align a pre-selected symptom list with the actual symptoms that may be produced by the variety of participants in the trial – in short, in this model, the verum group may produce a full range of symptoms, but is given credit for only a part;
and, second, and also by definition, since placebo response reflects the human capacity for suggestibility, the common research strategy, of providing a list of symptoms to a trial group, has the effect that those inclined to placebo response will naturally produce precisely those symptoms that have been placed in front of them! In essence, then, the control group is set up to respond to the entire range of symptoms expected of it – as reflected in the list of symptoms provided – in contrast to the fact that only selected symptoms are counted for the experimental group.
By these transactions, placebo response is actually statistically enhanced, at the expense of verum. The researcher might as well say, “Here, this is what we want you to produce.” Of course, the trial participant in the control group, who is suggestible, responds behaviorally with, “Sure, glad to oblige,” while the participant in the verum group can only shrug his shoulders and wait to see if there is a (real) reaction.
In brief, to repeat, this outcome rests on the tendency of placebo to model itself after symptoms that are the target of treatment, or intervention. But this is one of numerous characteristics of placebo response (distinguished from the ‘sugar pill’ per se) that have never been addressed by research scientists: simply stated, a patient treated for headache does not report that his stomach feels better as a result of the doctor’s prescription. Yet if both of these represent proving symptoms of the remedy being tested, then the verum subject is as likely to produce one as the other … but will only be credited if the one he produces happens to be found on the list.
It is true, as it might be argued, that some in the verum group will also show a placebo response, thus balancing the response of the control group. Yet, since some of those verum subjects who produce placebo symptoms, will also produce true verum symptoms, the latter will be lost to the final count: that is, they will fall below the raised bar – the enhanced performance of placebo across both groups – thus biasing trial outcome in the direction of placebo. This dynamic, of course, is in addition to the reduction in verum response because of the trial design – that is, the fact that only a limited number of symptoms from the proving record are allowed.
For clarity, this important dynamic may be thought of as an “induced placebo response.” A trial that does not specify target symptoms ahead of time, or which has the same symptom or symptoms as the legitimate objects of the trial for both groups is (as in trials of conventional medications) in a better position to approximate human response in a normal, as compared to the test, environment. Failure to identify and evaluate effects of such dynamics, in the testing situation, reflects the research team’s inadequate knowledge or training, regarding the nature of the homeopathic action, combined with the absence of any clinically viable definition of “placebo response” itself.
In an idealized trial of conventional medications, placebo and verum are on a level playing field: verum aims to eliminate a particular symptom, and by its nature, placebo develops in the same direction – aspirin and placebo both tend to eliminate headache pain, the question of the RCT being, of course, “which does a better job?” It is this qualitative equality of outcome – elimination of the same symptom, as between placebo and verum response – that makes it possible to conclude absence of bias in quantitative findings of a conventional trial, and, more important, relevance of those findings to medical practice in the real world.
The diversity of outcomes in proving trials of homeopathy, on the other hand, requires theoretical and practical, clinical expertise, to modify protocol design sufficiently to equalize outcomes, or at least account realistically for variations, other than by stereotyped application of terms such as “placebo.” But this is a difficult task, as I hope I have here and previously demonstrated. In fact, it is by no means clear that we have the ability to exclude significant confounders as potentially important factors in the outcomes of a randomized trial.
In short, in spite of the character of the idealized double blind trial, in eliminating bias, in fact we find, at least in this respect, that it can actually create bias, against verum. Recalling my observations in the first article of this series, regarding the way in which antidoting factors may favor placebo, we now have two examples of statistical bias, in favor of placebo, introduced by a combination of the very nature of homeopathic action (production of numerous symptoms); the nature of placebo response (to mimic targeted symptoms); and inadequacies in the double blind instrument, that is, that it is able to accurately record trial outcomes, but is unable to differentiate the sources of trial outcomes, leading, in the situations described above, to an undercount for verum and an elevated count for placebo.
It is, however, unfair, or inaccurate, to be satisfied with describing this as an “inadequacy” of the blinding principle: better is to realize that these considerations reflect limitations on the appropriate use of this important scientific instrument. After all, though skeptics apparently prefer to think otherwise, all instruments have limits. How can it be otherwise?
In summary, the statistical outcome of the blinded trial, while objectively and accurately recording the performance of verum v placebo in the trial, does not possess any prima facie relationship to medical practice in the real world, and misrepresents real medical practice to the degree to which these dynamics are not accounted for. What I have called the “induced placebo response,” however, is only a part of the problem, which I have highlighted in order to illustrate the subtle, unexpected, and even ironic ways in which the supposed objectivity of a scientific experiment can be compromised.
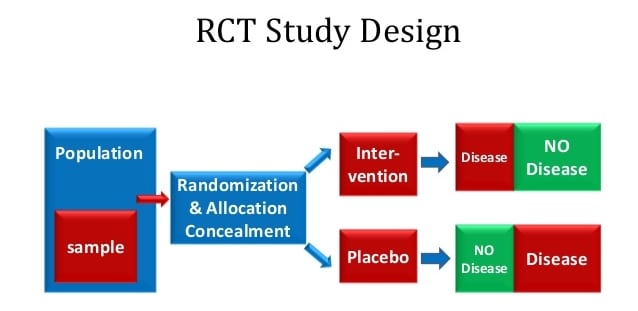
The RCT and Homeopathy: Randomization
Randomization is a simple procedure that distributes trial participants between control and experimental groups, as suggested by the name, on a random basis. In this way, any factors that tend toward a particular response to treatment are excluded from influencing the frequency of that response in either of the groups. In the event there is still concern that one group or the other is, on the whole, more responsive or more resistant to the treatment under investigation, the trial may be split in two, so that the sides are switched, and in the second half of the trial the experimental group becomes the control group, and vice versa. This ‘crossover’ technique effectively controls for vulnerability of the RCT to inequalities between the groups, at least in a trial of conventional treatments.
But in the homeopathic trial, in the circumstances discussed above, the crossover simply won’t work. This is clearly the case, since, as we discussed, some effects in enhancing placebo response effect only the placebo group. Thus, in a crossover, although the populations of the control and experimental groups are exchanged, the effects of the trial situation on outcomes remains the same – the effects are specific to the nature of the “control” itself, not to the characteristics of the participants who populate it.
A Second Layer of Observation – Selecting and Interpreting Outcomes
Simply, numbers do not speak for themselves. Two examples will provide a sample of problems that may be encountered designing a trial, and interpreting its outcomes, in the absence of reasonable clinical (i.e., not statistical) guidelines.
In a recent article,2 Brien et. al. use a list of symptoms as the basis for evaluating response to the homeopathic remedy. On this list, 5 symptoms were real symptoms found in the proving record for the test remedy; the other 5 symptoms were not proving symptoms of that remedy: thus, if a participant reported he had experienced one of the latter 5 symptoms, it was clear his response was a placebo response, rather than a response to the remedy. In measuring outcomes, however, the authors established a procedure in which verum symptoms were not counted if that same participant produced two symptoms from the second group. Though they did not clarify the point, it is clear they assumed that since that participant showed a fairly marked suggestibility, in producing two placebo responses, it was safe to assume that the supposed verum response was itself merely a result of suggestibility.
The problems with such an approach seem fairly obvious: without any knowledge whatsoever of how symptoms form in response to homeopathic remedies, nor even any “objective” proof that the remedies do or do not provoke such symptomatic responses, these authors introduced a completely arbitrary definition that resulted in a reduction in the “efficacy” of the homeopathic remedy, as reflected statistically through the blinded trial. This frankly incredible presumption reflects, furthermore, the inability of the randomized, blinded trial to understand trial outcomes, in short, to do anything more than count them. In the present case, the RCT reduced verum response – equally, to be sure (statistically) – in both the experimental and the control group, but obviously could not determine whether the verum symptom was a response to the real medicine, or to the sugar pill, in the case of the verum prover.
In other words, reduction of count for a participant in the control group is unobjectionable: there is no way that the apparent verum symptom could have been a response to the real medicine, because the participant did not receive the real medicine. But, reduction of count for a participant in the experimental group does nothing less than strike evidence of efficacy from the record!
All of us – patients, trial participants, authors, and statisticians – will respond to some medications, and not respond as much or as well to others, and will also respond to placebo. The presence of a placebo response in a participant in the verum group, in short, has no bearing on whether an accompanying verum response is truly a response to verum, as opposed to a placebo response that coincidentally mimics a verum response.
Brien et. al. also note that “…consumption [by trial participants] of alcohol and possible undisclosed recreational drug intake may minimize any homeopathic response. Lifestyle factors may colour the outcome, e.g., Belladonna-related symptoms of ‘headache’ and ‘sinking and rising sensation in his head’ were reported following high alcohol intake for the previous evening.” Yet, in their conclusions, the authors ignore their own caveats, citing the statistically negative outcome of the trial, for homeopathy, and recommending “…future research should focus on … those factors such as the therapeutic relationship and the process of the homeopathic consultation that may mediate the apparent success of the homeopathic process.”
Clearly, these authors demonstrate the point, that conclusions drawn from the statistical outcomes of the trial need not accurately reflect the significance of those numbers.
Discussion: Implications for Research
In the present paper, four situations have been discussed, that impact our ability to review results of objective research, with confidence that findings accurately reflect events in the real world. Normally, such research is, of course, subject to review for determining whether findings are statistically reliable. As a simple example, one might consider whether the sample size was sufficient to permit a confident statistical outcome, since too small a sample will be vulnerable to wild fluctuations in trial results: in the event a medical trial had, for example, five participants, 3 of whom showed ‘positive’ for a medicinal effect, that would reflect a 60% success rate for the medication. Yet a swing of one case, from positive to negative response, would alter the outcome to reflect a 60% failure rate for the medicine in question.
The present review of randomized trials, however, suggests that observational assessment of the trial design and outcomes – a kind of “clinical” evaluation of the experiment – is needed to ensure the logical, or “experiential” aspect of the trial does not introduce confounders of its own. We have, as stated, already identified four such potential confounders:
1) The first problem was actually identified in an article published last April,1 as previously referenced. In that situation, we reviewed the way in which antidoting substances could produce symptoms in participants in the control group, while antidoting, or eliminating symptoms in the verum group. The net effect of this differential action within a trial of homeopathic medicine, was to introduce a statistical advantage for placebo. This was the first time even a hint of bias, in the internal workings of a randomized trial, had been observed in the research literature.
As I have discussed before, it seems most likely that the impact of this confounder, on trial outcomes, would in most cases be quite small.
2) The second problem, identified in the present article, is reflected in the protocol design that establishes a list of symptoms, against which frequency of verum v placebo response is to be gauged. As we saw, the limitations on symptoms considered, results in the unintended effect that verum group draws from an impoverished range of allowable symptomatic responses, while, by definition, the selected symptom list established the full range of expectable responses for the placebo group. As discussed, this leads to a statistical advantage for placebo, within the so-called objective framework of the randomized, double blind study, a research design engineered to protect against observer bias, but clearly subject to potentially significant systematic bias, introduced by faulty trial design.
Compared to the first problem, this issue may potentially have a very dramatic impact: in the trial reviewed here, the symptom list that verum participants drew from was reduced from 1440 symptoms (identified for Belladonna by Hahnemann, in the Materia Medica Pura), to just 5 symptoms permitted by the protocol.
3) The third confounder, interfering with objectivity of outcomes in the RCT, is found in a process in which verum and control groups were both scored for production of real proving symptoms for the remedy being studied: thus, a positive response for a participant in the control group reflected a “point” for placebo. What is interesting in this study, is that the authors decided to discount verum symptoms from all participant responses – control and verum groups – if the responder also produced two symptoms that were not real proving symptoms as established in the materia medica. In short, verum symptoms produced by responders in the verum group were not counted, on the assumption that accompanying placebo responses suggested that the responder was so highly suggestible as to justify discounting even a potentially legitimate verum response!
Note: the purpose of this study was ostensibly to determine whether homeopathic remedies have any real effects, yet the authors concluded, in advance of the trial, that placebo responses would be given evidentiary weight in evaluating verum responses!
In all likelihood, it appears that this confounder would, like our first example, have a real, but minimal impact on the eventual statistical results.
4) Finally, we reviewed a paper reporting outcomes of a homeopathic proving trial, in which the authors noted factors that could likely have some impact on the experimental outcomes. Nevertheless, in their concluding comments, they ignored these factors, choosing instead to recommend that future research in homeopathy focus on mechanisms such as placebo response, to account for the appearance of success in real world practices. But it would seem, that a review of the effect of antidotes would be a more legitimate recommendation, based on these authors’ own observations.
In short, this example documents the way in which interpretation of data by the authors can effectively contradict a more objective record of experimental outcomes.
In summary, these examples illustrate a variety of ways in which the objectivity of the randomized, blinded trial may be compromised. The first three situations are peculiar to the situation of the homeopathic proving trial, or treatment trial. These paradoxical results are made possible by the fact that homeopathic remedies produce symptoms rather than just eliminate them, as with conventional medications. These results are also encouraged because, in context of the large numbers of symptomatic responses associated with homeopathic remedies, it becomes cumbersome and perhaps altogether impractical (financially or logistically) to implement a thoroughgoing symptom harvest. In an efficacy trial of conventional medications, on the other hand, the focus of the action of medicine is narrowly circumscribed, therefore easier and more practical to observe.
The decisions of the research team, to discount verum symptoms in case 3, above, and to disregard acknowledged confounders in case 4, represent, on the other hand, a type of bias introduced into research proceedings through the medium of human error – poor definition of terms, failure to address all aspects of the research situation in their summary. In short, these interpretative errors can have an effect on trials in homeopathic research as well as in trials of conventional medication.
What seems perfectly clear, is that future research efforts should be directed to evaluating the efficacy of randomized and blinded research trial itself, and should seek to identify as many situations as possible in order to measure the impact of therapeutic dynamics (e.g., the homeopathic mechanisms of action) and logical errors of the research team, on the accuracy – the credibility – of statistical and analytical results of published trials.
It is not accidental, nor unimportant, that our intuitive grasp of the situation agrees with the outcome of the conventional trial: we see that aspirin works, and the trial demonstrates that this is true – perception is vindicated. It is frankly beyond dispute, that we should be able to expect the same agreement as between perception and experimental outcomes, in the case of the homeopathic trial, or, failing this, we have a right to expect a responsible examination of the sources of disparity. I believe the present paper represents an important step in that direction.
Conclusion
The RCT has been involved as a major player in scientific research in recent decades. There certainly can be no justification in questioning the profound power of this research technology for controlling bias, in the effort to produce objective, and, more important, reliable, or credible, observational data. But, in case the skeptics in our midst haven’t noticed, the concept of the RCT, as an idealized instrument capable of easily measuring clinical process in homeopathy, has just been falsified.
This does not mean that the RCT can not be used to measure homeopathic action; indeed, at present, it is simply too early to tell, how significant the errors will be, that are introduced into the blinded statistical study by the transactions between blinding, placebo control, and those characteristics of homeopathic practice that distinguish it from conventional medicine. This is the first time, after all, that such paradoxical results have been shown in the workings of the double blinded trial. There is more to be done, to satisfy ourselves that the now dented instrument of the RCT can be relied on in all of the applications to which its faithful wish to put it, but we are not yet at the point, either, of concluding that more careful and more skillful design of trial protocols can’t overcome the obstacles in the path of reliable – credible – research.
In short, to value something highly, even to hold it very dear, is not to cherish it as an icon. It does not do to wave your magic wand, and chant three times, slowly, “Randomized! Double Blind! Placebo Controlled! Trial!! Randomized! Double Blind…!!” It does not generate confidence that the outcome of a trial can be trusted, just because its numbers add up; one can give a calculator to a child, but all one accomplishes by that, is to limit what one can expect from the calculator.
One quality the child lacks is perspective. Another is experience. These are keystones of knowledge and understanding. To the child, however, they don’t matter, as all he is concerned about are his numbers. But in science, we need to know if the numbers apply to real objects, and real processes, in the real world. As I believe I have clearly demonstrated – far beyond, frankly, what I expected to be able to do when I began – current practice in statistical research is as self-absorbed as a child, preoccupied with discovery of its own unfolding powers, but not yet at a stage of maturity as to grasp its relations to external reality.
I have to frankly laugh, though it be rude, at the thought that adherents of this methodology, in applying it to research into homeopathy, have managed to find not one, but at least four mechanisms (that I have identified) by which production of placebo response is enhanced in the Randomized Trial! Truly, it is a wonder that homeopathy does even as well as placebo in these trials, let alone outperform it!
Perhaps it all has something to do with the fact that so many researchers, as it appears, prefer to think of themselves as skeptics, rather than scientists, and to busy themselves more with doubt than with curiosity. And certainly, it has to do with the fact, that these self-same skeptics eschew the specialized knowledge of professionals in the fields they pretend to investigate. “Nonsense!” one can almost hear them saying. “If there were radio sources in deep space, surely even a poorly designed optical telescope would have found some piece of evidence for it by now!”
But perhaps one day, when someone combines understanding with calculation, and reason with randomization, the truth will finally be revealed. To be fair, it should be commented that statistical research, after all, is still a very young branch of science, and that there are, for good reason, no names amongst its practitioners that have been elevated to the pantheon, as Hahnemann to homeopathy, Freud, Jung, Adler, or Pavlov to psychology, Darwin or Mendel to biology, Einstein or Bohr to physics. This reflects, frankly, that there has as yet been no one to grasp the broader sweep and implications of statistical methodology in its various applications. It is after all the merest blink of an eye since it was realized, in the wake of the thalidomide scandal, that second generation testing should be a standard practice in such trials. Further, the ‘profession’ of statistical research hasn’t even been successful in helping its audience understand that ‘efficacy’ is unrelated to ‘safety,’ and that the RCT has nothing to say about the latter.
Simply put, this is still a youthful science, a useful and promising one, to be sure, but immature, and even naive, zealous, and self-satisfied, in the way of the young. One only hopes that, as they continue to stump for repression of medical practices they don’t like, for whatever personal motives they may have, these supposed skeptics will at least report honestly to the public and to government leaders, that their claim to perfect objectivity has been slain.
References
1 Shere, Neil D. 2005. Proving Homeopathy:, hpathy ezine (April),
2 Brien, et. al. 2003. Ultramolecular homeopathy has no observable clinical effects. A randomized, double-blind, placebo-controlled proving trial of Belladonna 30C.” British Journal of Clinical Pharmacology, 56:562-568.